



NVIDIA將於9月25日開源Audio2Face模型與SDK
【NVIDIA將於9月25日開源Audio2Face模型與SDK,讓所有遊戲和3D應用開發者都能夠構建並部署帶有先進動畫的高精度角色。NVIDIA將開放Audio2Face的訓練框架,任何人都可以針對特定用途對現有模型進行微調與定制。
NVIDIA Audio2Face透過生成式AI驅動的即時面部動畫與嘴形同步,加速寫實數字角色的創作流程。Audio2Face利用AI根據音頻輸入生成逼真的面部動畫。這項技術通過分析音素、語調等聲學特徵,創建動畫數據流,並將其映射至角色的面部表情。這些動畫數據既可用於離線渲染預設的資產,也可即時傳輸到動態的、由AI驅動的角色,實現精確的嘴形同步與情感表達。
Audio2Face模型已廣泛應用於遊戲、媒體娛樂以及客戶服務等行業。許多獨立軟件廠商ISV與遊戲開發商都在其應用中採用了Audio2Face。遊戲開發者包括Codemasters、GSC Game World、網易、完美世界。ISV則包括Convai、Inworld AI、Reallusion、Streamlabs和UneeQ。
以下是開源工具的完整列表,更多詳情請查看面向遊戲開發的NVIDIA ACE:
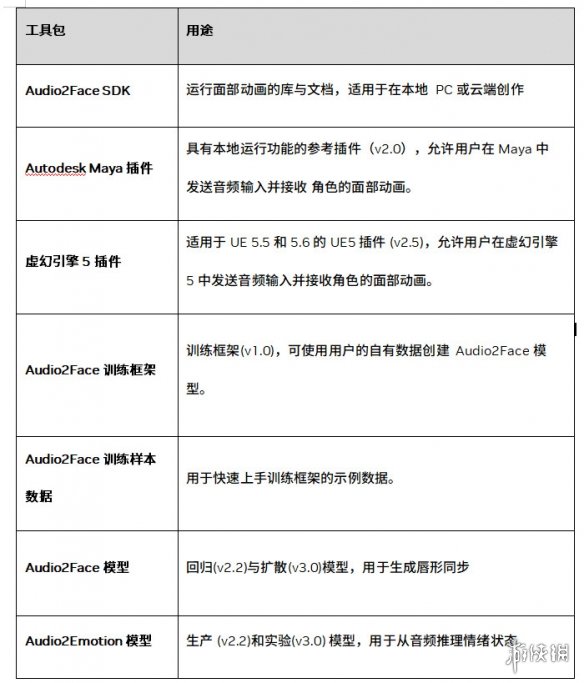
- **Audio2Face SDK**:運行面部動畫的庫與文檔,適用於在本地PC或雲端創作。
- **Autodesk Maya插件**:具有本地運行功能的參考插件(v2.0),允許用戶在Maya中發送音頻輸入並接收角色的面部動畫。
- **虛幻引擎 5 插件**:適用於UE 5.5 和 5.6 的 UE5 插件 (v2.5),允許用戶在虛幻引擎5中發送音頻輸入並接收角色的面部動畫。
- **Audio2Face訓練框架**:訓練框架(v1.0),可使用用戶的自有數據創建Audio2Face模型。
- **Audio2Face訓練樣本數據**:用於快速上手訓練框架的示例數據。
- **Audio2Face模型**:回歸(v2.2)與擴散(v3.0)模型,用於生成唇形同步。
- **Audio2Emotion模型**:生產 (v2.2)和實驗(v3.0) 模型,用於從音頻推斷情緒狀態。】
